Code
iris2 <- subset(iris, Species %in% c("setosa", "versicolor"))C5025HF
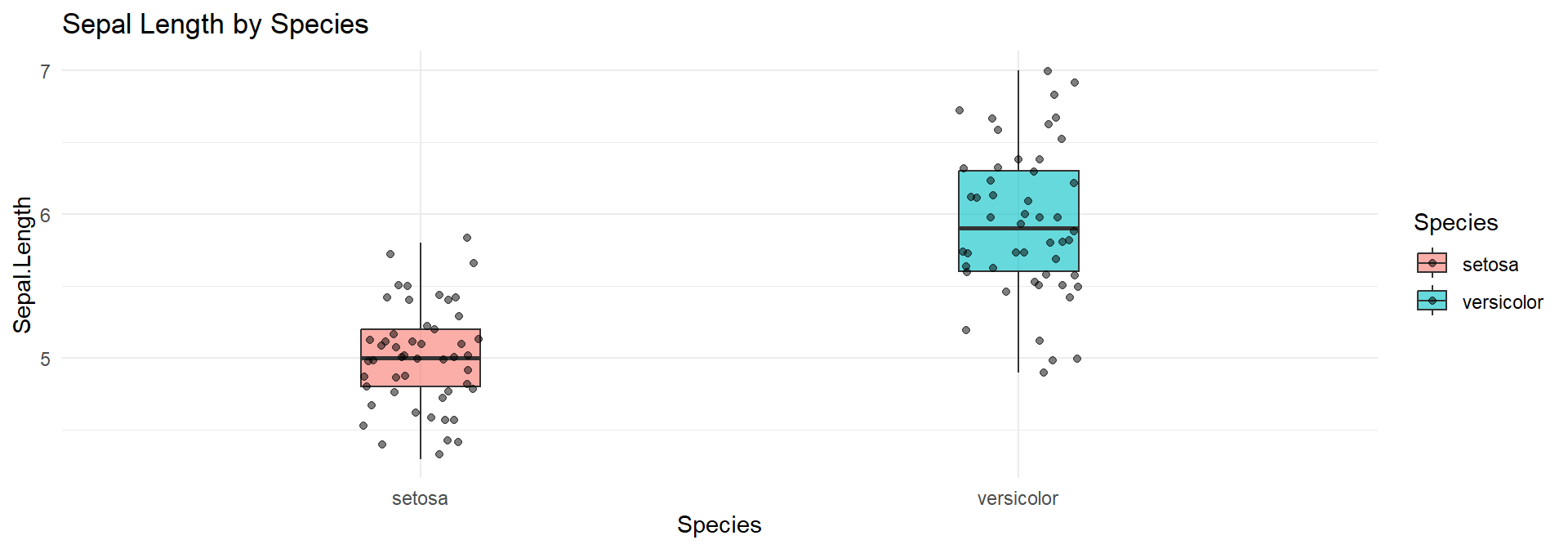
Compare Sepal.Length between two species. We subset to two species for a t-test:
iris2 <- subset(iris, Species %in% c("setosa", "versicolor"))library(ggplot2)
ggplot(iris2, aes(x = Species, y = Sepal.Length, fill = Species)) +
geom_boxplot(alpha = 0.6,width=0.2) +
geom_jitter(width = 0.1, alpha = 0.5) +
theme_minimal() +
ggtitle("Sepal Length by Species")shapiro.test(iris2$Sepal.Length[iris2$Species=="setosa"])
Shapiro-Wilk normality test
data: iris2$Sepal.Length[iris2$Species == "setosa"]
W = 0.9777, p-value = 0.4595shapiro.test(iris2$Sepal.Length[iris2$Species=="versicolor"])
Shapiro-Wilk normality test
data: iris2$Sepal.Length[iris2$Species == "versicolor"]
W = 0.97784, p-value = 0.4647library(ggplot2)
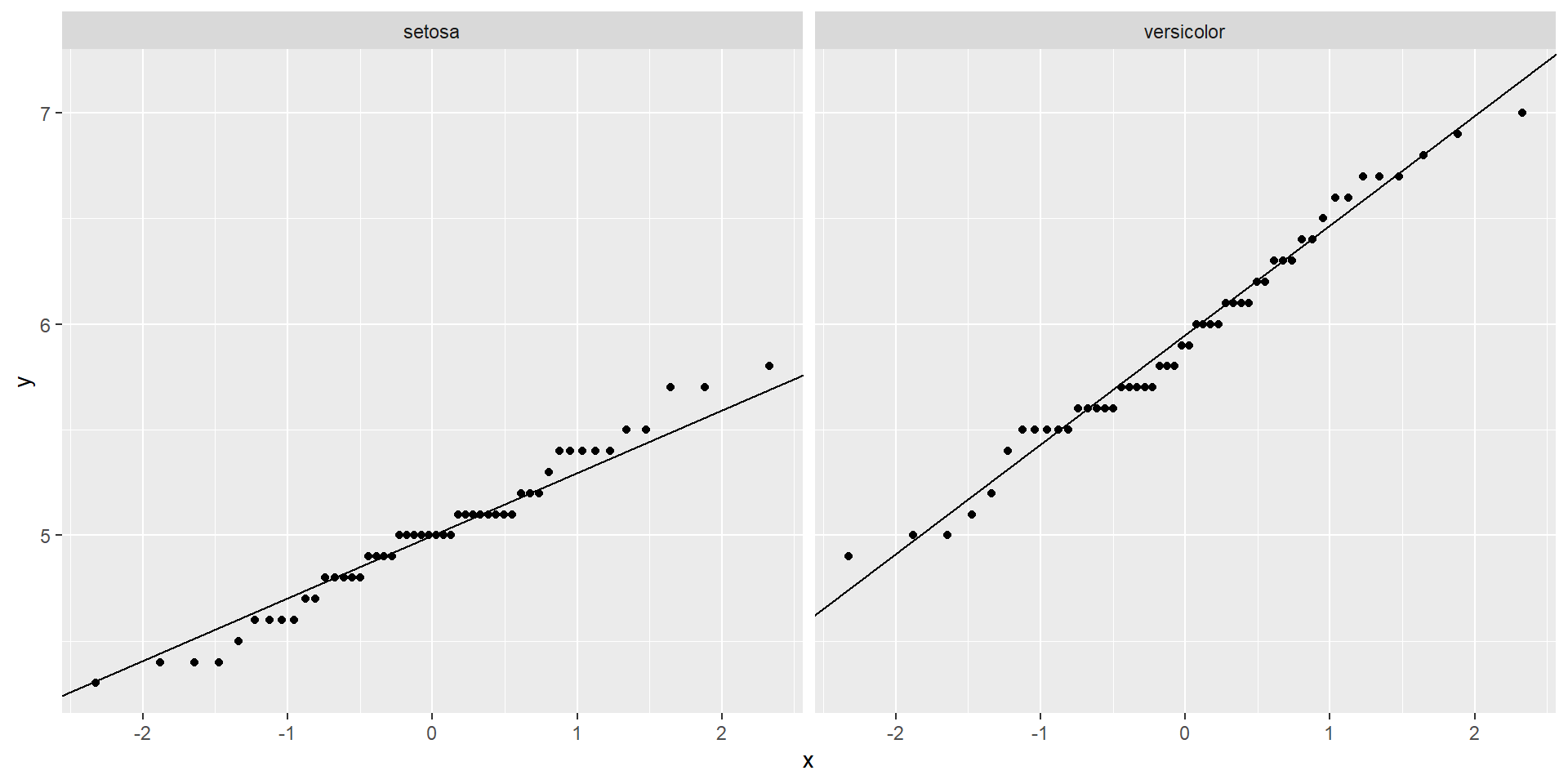
ggplot(iris2, aes(sample = Sepal.Length)) + stat_qq() + stat_qq_line() + facet_wrap(~Species)library(car)
leveneTest(Sepal.Length ~ Species, data = iris2)Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 1 8.1727 0.005196 **
98
---
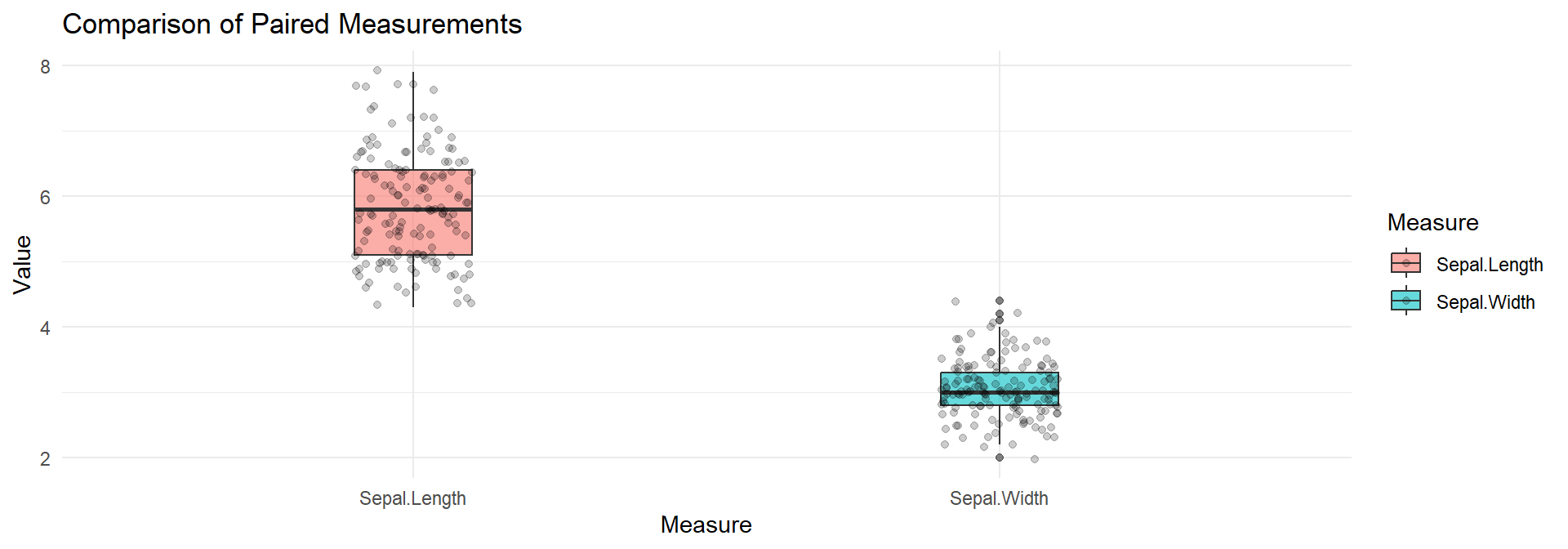
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Compare Sepal.Length vs Sepal.Width for the same flowers. Since these measurements come from the same flower, they are paired.
# Reshape data to long format for plotting
library(tidyr)
iris_long <- pivot_longer(iris,
cols = c("Sepal.Length", "Sepal.Width"),
names_to = "Measure",
values_to = "Value")
ggplot(iris_long, aes(x = Measure, y = Value, fill = Measure)) +
geom_boxplot(alpha = 0.6,width=0.2) +
geom_jitter(width = 0.1, alpha = 0.2) +
theme_minimal() +
ggtitle("Comparison of Paired Measurements")diffs <- iris$Sepal.Length - iris$Sepal.Width
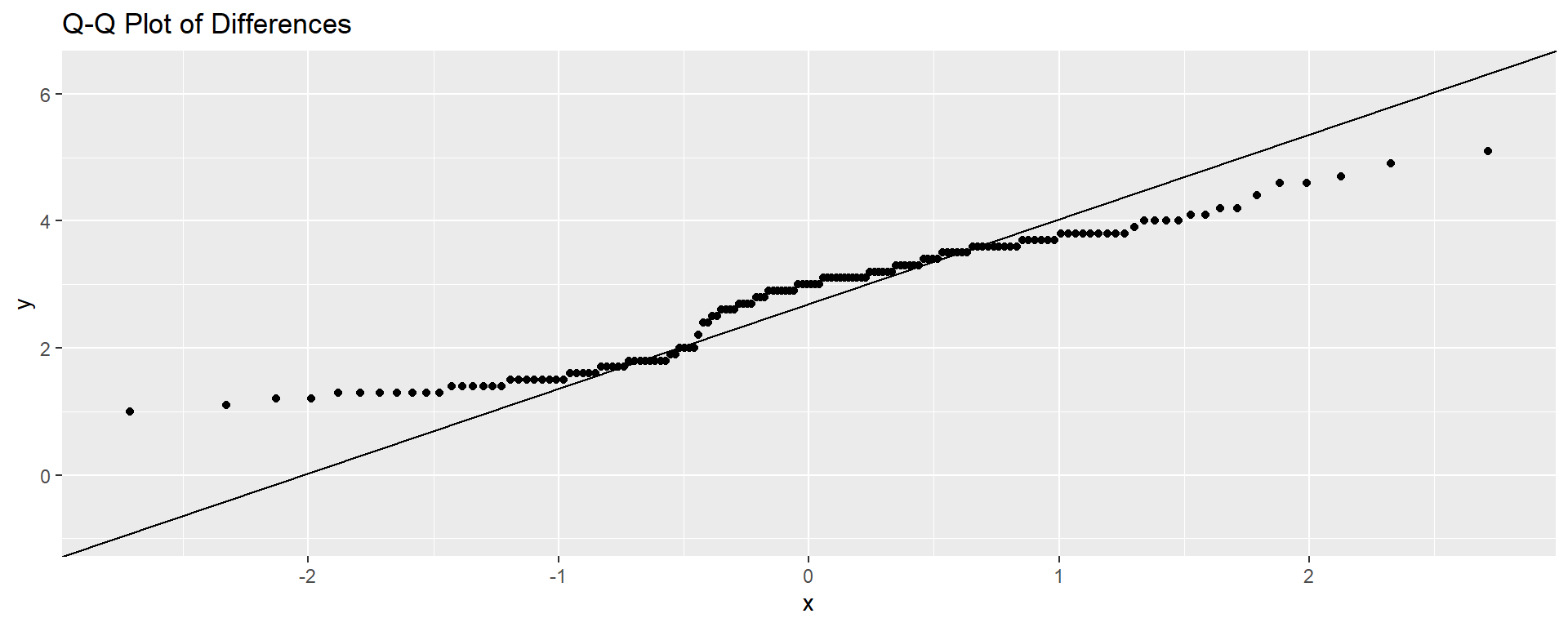
shapiro.test(diffs)
Shapiro-Wilk normality test
data: diffs
W = 0.94628, p-value = 1.628e-05ggplot(data.frame(diffs), aes(sample = diffs)) + stat_qq() + stat_qq_line() +
ggtitle("Q-Q Plot of Differences")Test independence between Species and a discretised version of Sepal.Width. We bin Sepal.Width:
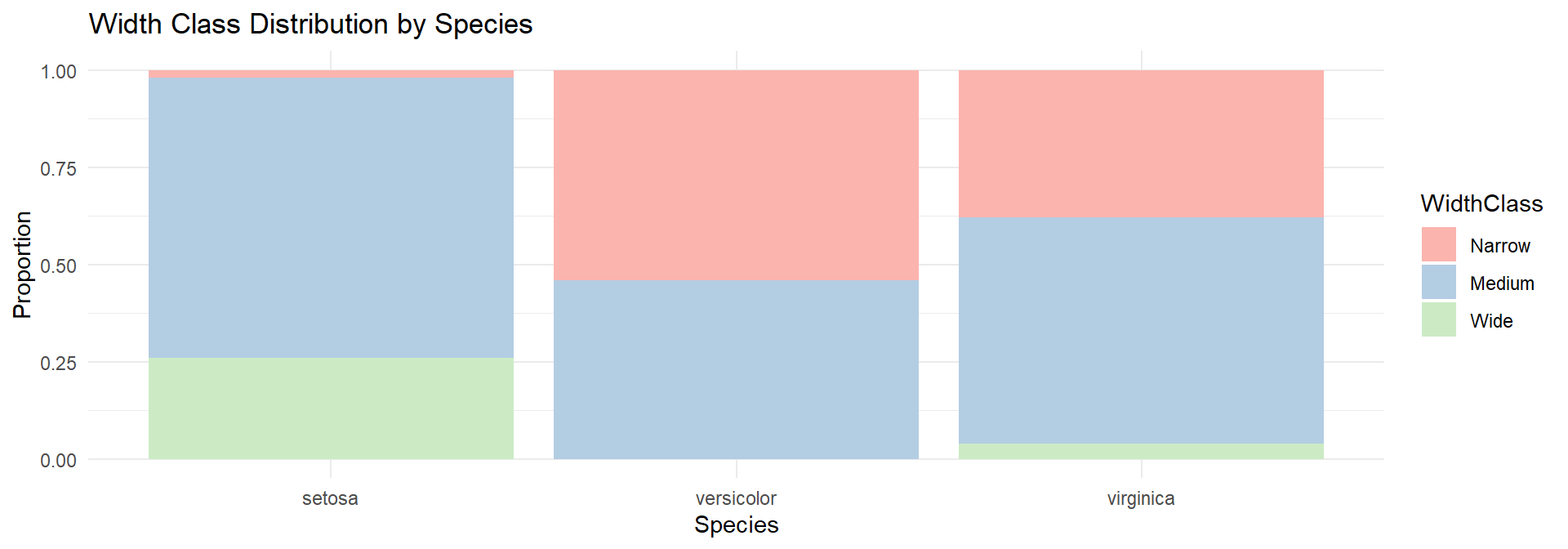
iris$WidthClass <- cut(iris$Sepal.Width, breaks = 3, labels = c("Narrow", "Medium", "Wide"))
tab <- table(iris$Species, iris$WidthClass)ggplot(iris, aes(x = Species, fill = WidthClass)) +
geom_bar(position = "fill") +
theme_minimal() +
labs(y = "Proportion", title = "Width Class Distribution by Species") +
scale_fill_brewer(palette = "Pastel1")Compare Petal.Length across all three species.
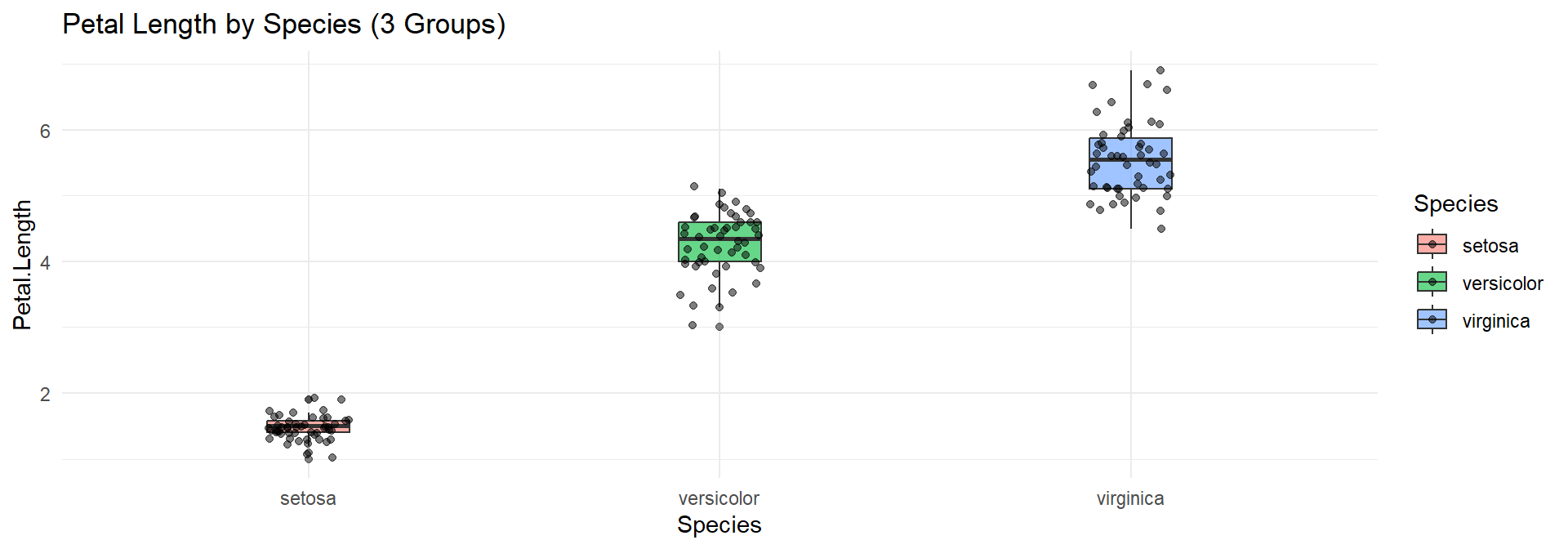
iris$Species <- factor(iris$Species)ggplot(iris, aes(x = Species, y = Petal.Length, fill = Species)) +
geom_boxplot(alpha = 0.6,width=0.2) +
geom_jitter(width = 0.1, alpha = 0.5) +
theme_minimal() +
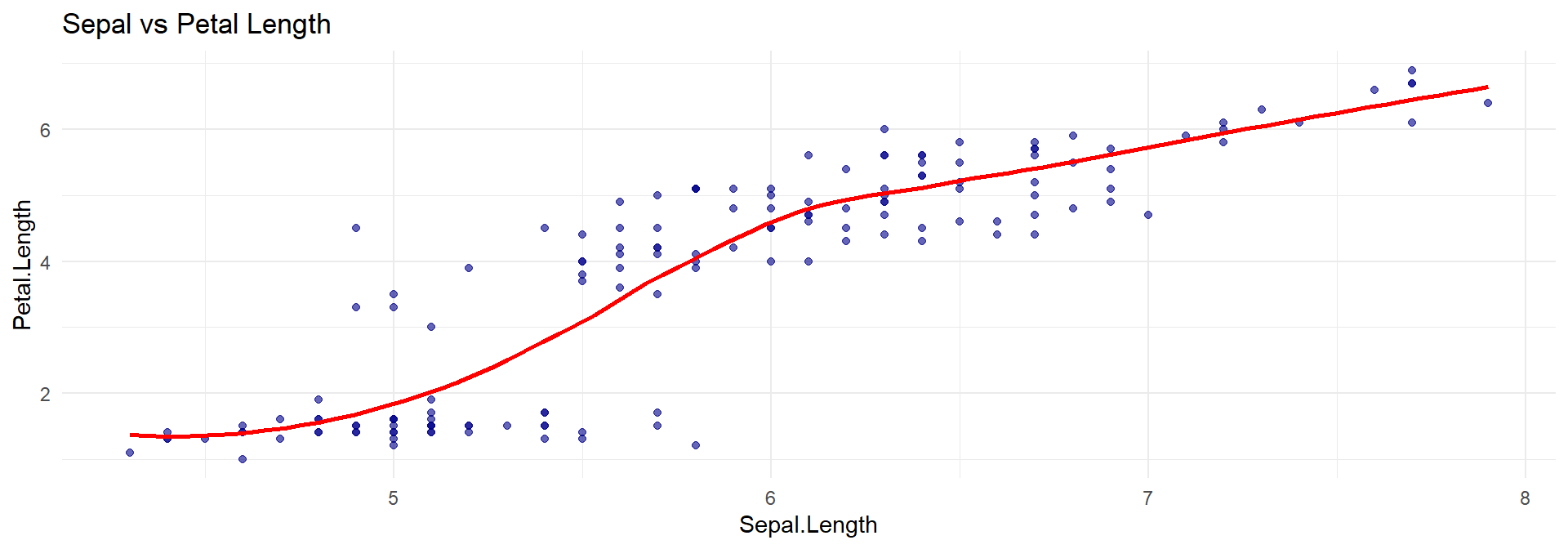
ggtitle("Petal Length by Species (3 Groups)")Assess the relationship between Sepal.Length and Petal.Length.
ggplot(iris, aes(x = Sepal.Length, y = Petal.Length)) +
geom_point(alpha = 0.6, color = "darkblue") +
geom_smooth(method = "loess", color = "red", se = FALSE) +
theme_minimal() +
ggtitle("Sepal vs Petal Length")